
We test your AI agents from where your users are
and tell you when the answers are wrong.
Agents Monitored
Total Tests Completed









You did it. You shipped an AI agent to production.
Grafana says 200 OK. LangSmith trace looks clean.
Your users just got a hallucinated answer. By the time it shows up in your support queue, hundreds already saw it.
It works in New York. It's broken in São Paulo.
Bot detection, geo-routing, and CDN behavior change what your users actually get.
Your reasoning trace can't see this. Neither can your users file a ticket from a market you forgot to check.
OpenAI pushed a model update last night.
Your LangChain pipeline didn't change. But your agent's answers did.
Your eval suite passed. Your users noticed first. You'll spend tomorrow in traces trying to figure out when it started.
What we do
Your monitoring is inside-out.Your users are outside.
Answer quality
We evaluate whether your agent's responses are actually correct.
Uptime & reachability
We test reachability from real locations your users are in.
Drift detection
We catch behavior changes from upstream model updates instantly.
Guardrail validation
We verify your agent stays within the boundaries you set.
Residential testing
We run every test from real devices on residential networks.
Alerting
We notify you through Slack, PagerDuty, email, or webhook.
It's not AI agents for monitoring. It's monitoring for AI agents, from where your users are.
It's not AI agents for monitoring. It's monitoring for AI agents, from where your users are.
Three steps.
No code changes.
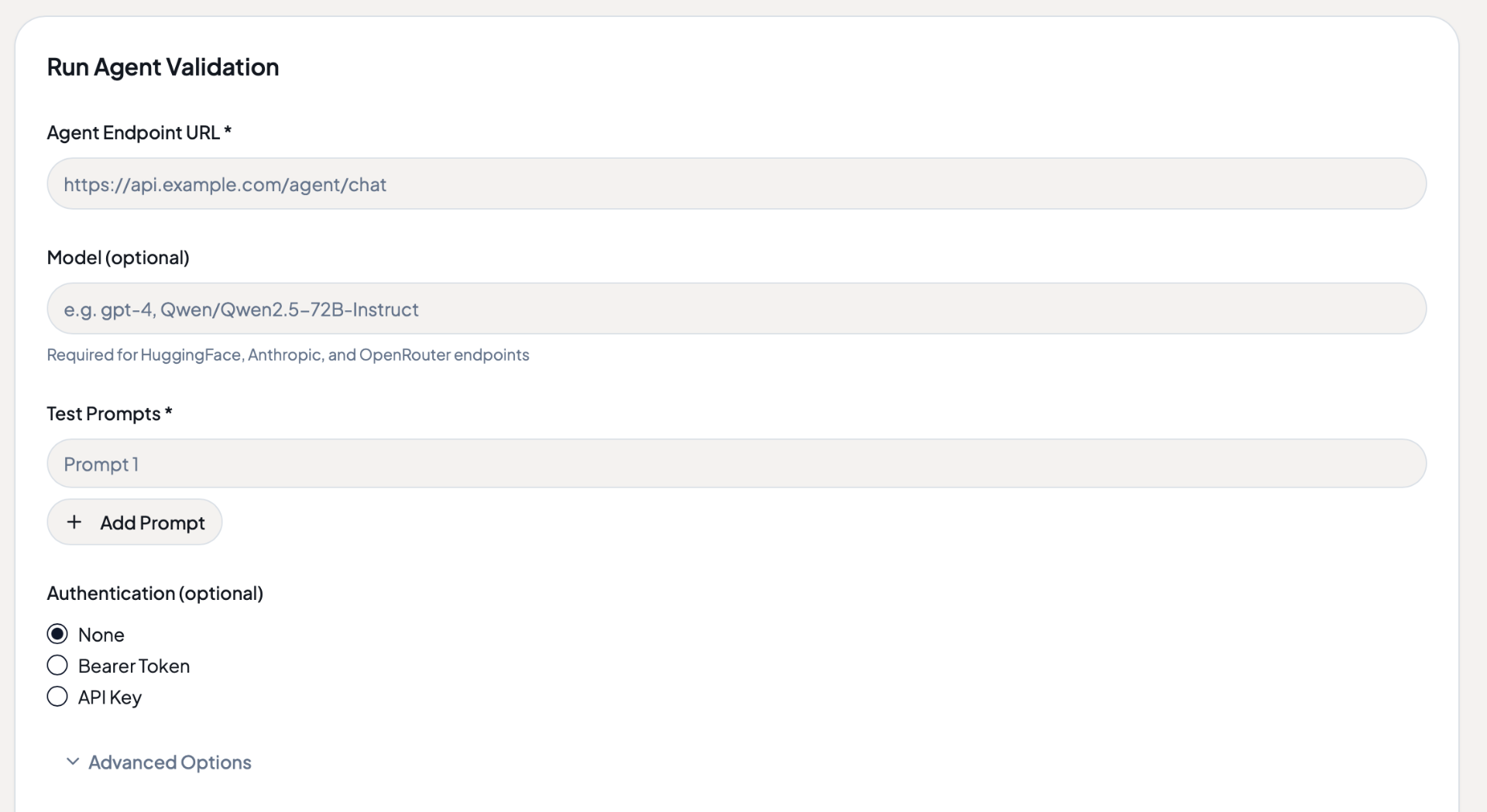
Point
Give Agent Status your agent's endpoint and a few test prompts. You don't need to install an SDK or change any code.
Under 2 minutes to set up
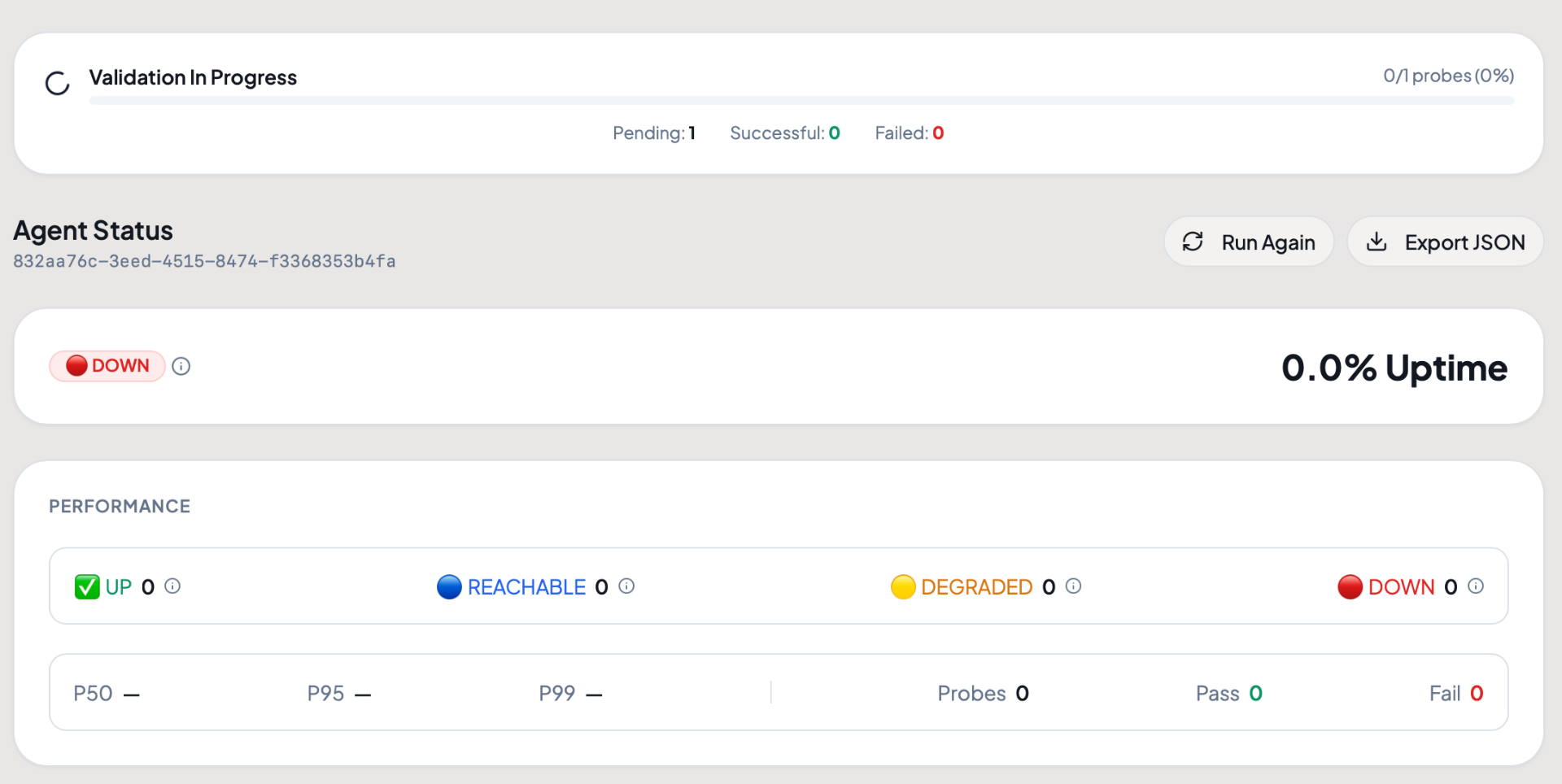
Test
Agent Status sends real prompts on a schedule you choose and automatically verifies correctness. Every test runs from a real device on a real network.
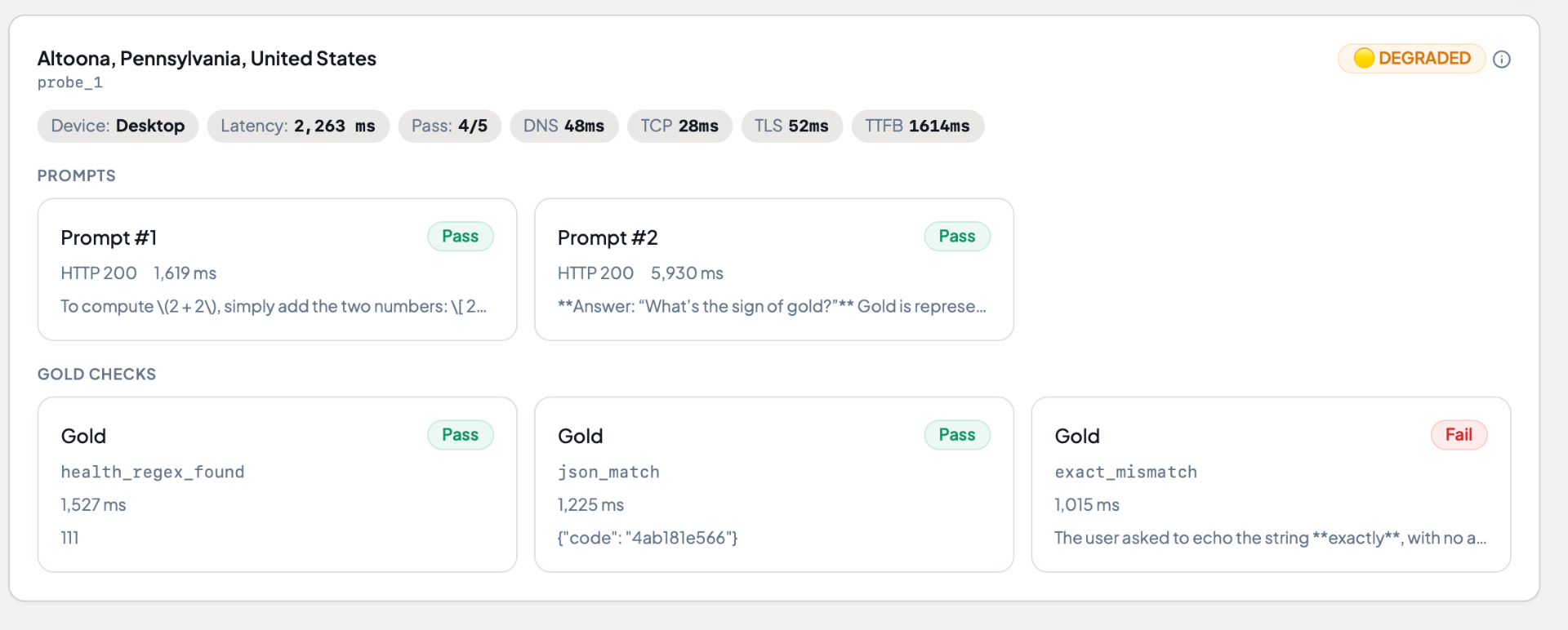
Know
Report card, status page, instant alerts. When something breaks, structured attribution tells you why so you fix the right thing.
We get it. You sleep.
Things happen.
Don't be the team that finds out from a support ticket.
Health check passed. Status 200, latency 120ms from us-east-1.
Test complete. Evaluation prompts: 3/3 passing. Math ✓ JSON ✓ Echo ✓. Accuracy: 94%.
Health check passed. Status 200, latency 118ms from us-east-1.
⚠️ Evaluation regression. JSON check returning markdown-wrapped response. Accuracy dropped to 61%. Attribution: model drift.
Health check passed. Status 200, latency 122ms from us-east-1.
"Your API returns markdown in JSON responses. Our parser has been broken since Tuesday."
Agent Status caught it at 2am Tuesday. Your monitoring still says "all clear" on Thursday.
What we catch that your current
monitoring doesn't.
Scenario 01 // Failure
Your support agent is live in 12 countries.
No visibility into which regions are receiving incorrect or degraded responses from your agent.
Outcome // Agent Status
Regional accuracy breakdown in real time.
Tests run from real devices in each region, giving you per-country accuracy scores and instant alerts when any region degrades.
Scenario 02 // Drift
You deployed a new model version on Friday.
No way to verify the new model still passes your quality bar over the weekend.
Outcome // Agent Status
Continuous evaluation catches regressions automatically.
Scheduled evaluation prompts run 24/7. If accuracy drops after a deploy, you get alerted before users notice.
Scenario 03 // Blind Spot
Your agent passed every test in staging.
Production traffic patterns differ from staging. Your agent is hallucinating on real-world queries.
Outcome // Agent Status
Production-grade testing from outside your infra.
Real devices on real networks test your live endpoint — the same path your users take. Staging ≠ production.
Scenario 04 // Proof
Your SLA says 99.9% accuracy.
Can you prove it with third-party data? Your internal metrics aren't enough.
Outcome // Agent Status
Independent, audit-ready verification.
Third-party accuracy data from outside your infrastructure. Reports your customers and auditors can trust.
Scenario 05 // Silence
A customer files a ticket at 10am.
The agent broke at 3am and nobody knew. Seven hours of silent failure.
Outcome // Agent Status
Instant break detection & alerting.
Slack, email, webhook alerts fire within minutes of failure. No more silent outages.
Scenario 01 // Failure
Your support agent is live in 12 countries.
No visibility into which regions are receiving incorrect or degraded responses from your agent.
Outcome // Agent Status
Regional accuracy breakdown in real time.
Tests run from real devices in each region, giving you per-country accuracy scores and instant alerts when any region degrades.
Scenario 02 // Drift
You deployed a new model version on Friday.
No way to verify the new model still passes your quality bar over the weekend.
Outcome // Agent Status
Continuous evaluation catches regressions automatically.
Scheduled evaluation prompts run 24/7. If accuracy drops after a deploy, you get alerted before users notice.
Scenario 03 // Blind Spot
Your agent passed every test in staging.
Production traffic patterns differ from staging. Your agent is hallucinating on real-world queries.
Outcome // Agent Status
Production-grade testing from outside your infra.
Real devices on real networks test your live endpoint — the same path your users take. Staging ≠ production.
Scenario 04 // Proof
Your SLA says 99.9% accuracy.
Can you prove it with third-party data? Your internal metrics aren't enough.
Outcome // Agent Status
Independent, audit-ready verification.
Third-party accuracy data from outside your infrastructure. Reports your customers and auditors can trust.
Scenario 05 // Silence
A customer files a ticket at 10am.
The agent broke at 3am and nobody knew. Seven hours of silent failure.
Outcome // Agent Status
Instant break detection & alerting.
Slack, email, webhook alerts fire within minutes of failure. No more silent outages.
Test an agent live. Get results in 30 seconds.
Choose how to test:
Monitor agents built on
 OpenAI
OpenAI Claude
Claude Google
Google Azure
Azure AWS Bedrock
AWS Bedrock LangChain
LangChain Fetch.ai
Fetch.ai Forethought
Forethought ElevenLabs
ElevenLabs Retell
Retell Perplexity
Perplexity Poe
Poe DevinSwarmsVoiceflowBotpressCrewAIHuggingFaceGoogle ADK / A2ANanda A2A
DevinSwarmsVoiceflowBotpressCrewAIHuggingFaceGoogle ADK / A2ANanda A2A